Google has declared war on the independent media and has begun blocking emails from NaturalNews from getting to our readers. We recommend GoodGopher.com as a free, uncensored email receiving service, or ProtonMail.com as a free, encrypted email send and receive service.
Speaking to attendees at a deep learning conference in London last month, there was one particularly noteworthy recurring theme: humility, or at least, the need for it.
While companies like Google are confidently pronouncing that we live in an “AI-first age,” with machine learning breaking new ground in areas like speech and image recognition, those at the front lines of AI research are keen to point out that there’s still a lot of work to be done. Just because we have digital assistants that sound like the talking computers in movies doesn’t mean we’re much closer to creating true artificial intelligence.
Problems include the need for vast amounts of data to power deep learning systems; our inability to create AI that is good at more than one task; and the lack of insight we have into how these systems work in the first place. Machine learning in 2016 is creating brilliant tools, but they can be hard to explain, costly to train, and often mysterious even to their creators. Let’s take a look at these challenges in more detail:
First you get the data, then you get the AI
We all know that artificial intelligence needs data to learn about the world, but we often overlook how much data is involved. These systems don’t just require more information than humans to understand concepts or recognize features, they require hundreds of thousands times more, says Neil Lawrence, a professor of machine learning at the University of Sheffield and part of Amazon’s AI team. “And if you look at all the applications domains were deep learning is successful you’ll see they’re domains where we can acquire a lot of data,” says Lawrence, giving the example of speech and image recognition. Here, big tech firms like Google and Facebook have access to mountains of data (for example, your voice searches on Android), making it much easier to create useful tools.
Right now, says Lawrence, data is like coal was in the early years of the Industrial Revolution. He gives the example of Thomas Newcomen — an Englishman who, in 1712, invented a primitive version of the steam engine that ran on coal, about 60 years before James Watt did. Newcomen’s invention wasn’t very good: compared to Watt’s machine, it was inefficient and costly to run. That meant it was put to work only in coalfields — where the fuel was plentiful enough to overcome the machine’s handicaps.
A screenshot from Facebook’s open-source image recognition tools.
Lawrence suggests that all around the world there are hundreds of Newcomens working on their own machine learning models. They might be revolutionary, but without the data to make them work, we’ll never know. Big tech firms like Google, Facebook, and Microsoft are today’s coal mines. They have abundant data and so can afford to run inefficient machine learning systems, and improve them. Smaller startups might have good ideas, but they won’t be able to follow through without data.
The problem is even bigger when you look at areas where data is difficult to get your hands on. Take health care, for example, where AI is being used for machine vision tasks like recognizing tumors in X-ray scans, but where digitized data can be sparse. As Lawrence points out, the tricky bit here is that it’s “generally considered unethical to force people to become sick to acquire data.” (That’s what makes deals like that struck between Google and the National Health Service in the UK so significant.) The problem, says Lawrence, is not really about finding ways to distribute data, but about making our deep learning systems more efficient and able to work with less data. And just like Watt’s improvements, that might take another 60 years.
Specialization is for insects — AI needs to be able to multitask
There’s another key problem with deep learning: the fact that all our current systems are, essentially, idiot savants. Once they’ve been trained, they can be incredibly efficient at tasks like recognizing cats or playing Atari games, says Google DeepMind research scientist Raia Hadsell. But “there is no neural network in the world, and no method right now that can be trained to identify objects and images, play Space Invaders, and listen to music.” (Neural networks are the building blocks of deep learning systems.)
The problem is even worse than that, though. When Google’s DeepMind announced in February last year that it’d built a system that could beat 49 Atari games, it was certainly a massive achievement, but each time it beat a game the system needed to be retrained to beat the next one. As Hadsell points out, you can’t try to learn all the different games at once, as the rules end up interfering with one another. You can learn them one at a time — but you end up forgetting whatever you knew about previous games. “To get to artificial general intelligence we need something that can learn multiple tasks,” says Hadsell. “But we can’t even learn multiple games.”
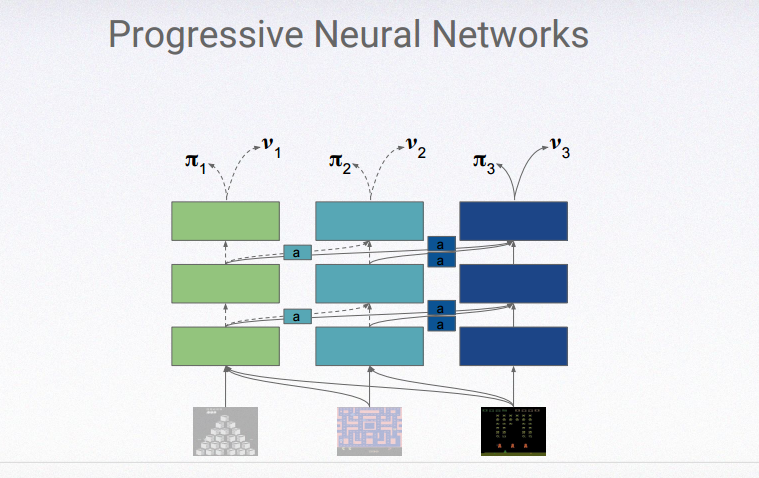
A solution to this might be something called progressive neural networks — this means connecting separate deep learning systems together so that they can pass on certain bits of information. In a paper published on this topic in June, Hadsell and her team showed how their progressive neural nets were able to adapt to games of Pong that varied in small ways (in one version the colors were inverted; in another the controls were flipped) much faster than a normal neural net, which had to learn each game from scratch.
The basic layout of a progressive neural network. (Image credit: DeepMind / Raia Hadsell)
It’s a promising method, and in more recent experiments it’s even been applied to robotic arms — speeding up their learning process from a matter of weeks to just a single day. However, there are significant limitations, with Hadsell noting that progressive neural networks can’t simply keep on adding new tasks to their memory. If you keep chaining systems together, sooner or later you end up with a model that is “too large to be tractable,” she says. And that’s when the different tasks being managed are essentially similar — creating a human-level intelligence that can write a poem, solve differential equations, and design a chair is something else altogether.
It’s only real intelligence if you can show your working
Another major challenge is understanding how artificial intelligence reaches its conclusions in the first place. Neural networks are usually inscrutable to observers. Although we know how they’re put together and the information that goes in them, the reasons why they come to certain decisions usually goes unexplained.
A good demonstration of this problem comes from an experiment at Virginia Tech. Researchers created what is essentially an eye-tracking system for a neural network, which records which pixels the computer looks at first. The researchers showed the neural net pictures of a bedroom and asked the AI: “What is covering the windows?” They found that instead of looking at the windows, the AI looked at the floor. Then, if it found a bed, it gave the answer “there are curtains covering the windows.” This happened to be right, but only because of the limited data the network had been trained on. Based on the pictures it had been shown, the neural net had deduced that if it was in a bedroom there would be curtains on the windows. So when it saw a bed, it stopped looking — it had, in its eyes, seen curtains. Logical, of course, but also daft. A lot of bedrooms don’t have curtains!
Eye-tracking is one way of shining some light on the inner workings, but another might be to build more coherence into deep learning systems from the get-go. One way of doing this is revisiting an old, unfashionable strand of machine learning known as symbolic AI or Good Old-Fashioned Artificial Intelligence (GOFAI), says Murray Shanahan, a professor of cognitive robotics at Imperial College London (and also the scientific advisor on Ex Machina). This is based on the hypothesis that what goes on in the mind can be reduced to basic logic, where the world is defined by a complex dictionary of symbols. By combining these symbols — which represent actions, events, objects, etc. — you can basically synthesize thinking. (If creating an AI this way sounds like a monstrous, unthinkable task, just imagine trying it on computers that still run on magnetic tape.)
Shanahan’s proposal is that we take the symbolic descriptions of GOFAI and combine them with deep learning. These would provide the systems with a starting point for understanding the world, rather than just feeding them data and waiting for them to notice patterns. This, he says, might not only solve the transparency problem of AI, but also the problem of transfer learning outlined by Hadsell. “It’s all very well to say that Breakout is similar to Pong because they’ve both got paddles and balls, but human level cognition makes these types of connections on a much more dramatic scale,” says Shanahan. “Like the connection between the structure of the atom and the structure of the solar system.”
Shanahan and his team at Imperial are working on the new method (which they call deep symbolic reinforcement learning) and have published some small experiments. It’s still in its infancy, and finding out whether it will scale up to larger systems and different types of data will be telling. However, there’s every chance it could develop into something more. After all, deep learning itself was an unloved department of AI until researchers began to plug in the cheap data and abundant processing power made available in recent years. Maybe it’s time for another blast from AI’s past to try its skills in a new environment.
All content posted on this site is protected under Free Speech. Robotics.News is not responsible for content written by contributing authors. The information on this site is provided for educational and entertainment purposes only. It is not intended as a substitute for professional advice of any kind. Robotics.News assumes no responsibility for the use or misuse of this material. All trademarks, registered trademarks and service marks mentioned on this site are the property of their respective owners.